
My Software Estimation Process
You got your chocolate in my peanut butter! No, you got your peanut butter in my chocolate!

Introduction
Inspired by my friend Kevin @ HackerOverflow, I thought I would describe the estimation process I use, and what I recommend to the people who work with me.
It is a process with three parts:
Break the work down into more-or-less independent tasks/stories. This should be a collaborative process, so everyone feels like they understand what the task or story accomplishes. It is not necessarily important for the group members to know exactly how to implement the task, just that they know what needs to be done.
“More or less independent” essentially means “a task that may require certain other tasks to be done first, but generally does not have any dependencies on other tasks that might be in-process at the same time.”
In general, if you do find that you have a task that is entangled with, and needs to be done at the time as another task, in reality, that should probably be thought of as one somewhat larger task.
For each task, gather independent time estimates from each member of the group. Capture all of those estimates for the next step. Note: these need to be good faith estimates. If the team members are being deliberately difficult, this approach won’t work.
“independent estimates” means that the members are estimating without feedback or “anchoring” from other members. Ideally this means that they all generate their estimates at the same time. However, as long as they don’t discuss the estimates before they make them, it’s ok for them to happen at arbitrary times.
This is a simplified approach to the Delphi Method of estimating.
This approach is similar to Planning Poker, which is well-described in the book: Agile Estimating and Planning by Mike Cohn. Note that we do not attempt to get consensus from the team members. (In fact, we want to avoid consensus at this point)
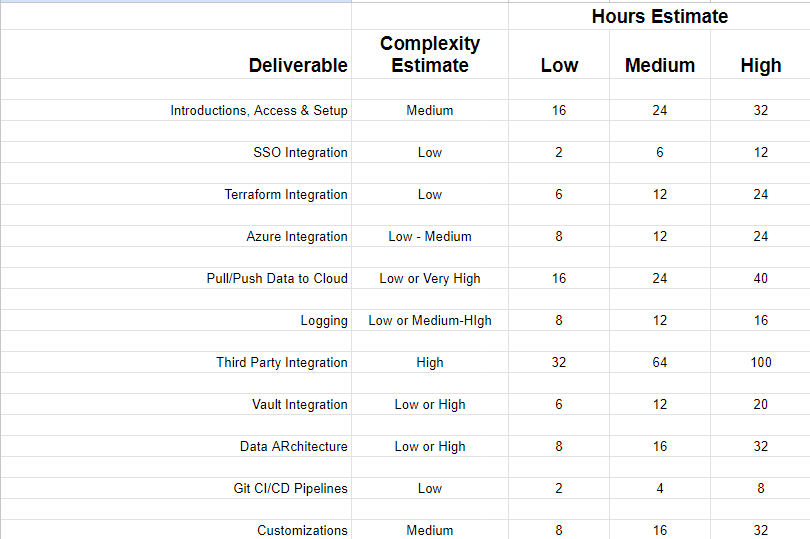
Here’s an example of a task list

For each task, identify the lowest estimate, the highest estimate, and calculate the average of all of the estimates. Use these as the inputs to a Monte Carlo simulation of the project
For more information on Monte Carlo simulations, read Waltzing With Bears, by DeMarco & Lister.
In the years since that book was written, there are lots of online tools that can accept your inputs and generate simulations from them.
There are also lots of articles about how you can use Excel to do this, so you don’t even need a dedicated tool.
The output of this process should be modelled as a histogram, representing the results for the thousands of simulations. Most of the tools will generate a histogram for you. Identify the time value <X> that is at the 80% level (i.e. the value where 80% of the other estimates are below it, and 20% are above it)
Example Histogram:

note that this histogram is not related to the task list above Note: Various tools will calculate the 80% for you, but as a general rule of thumb, it will be halfway down the downslope on the right hand side, so roughly 3350 in this diagram.
Note 2: It doesn’t have to be 80%. That just seems like the number that everyone likes.

Now, you can say to your customers/managers/leadership that you have an 80% confidence that it will take <X> amount of time or less.
Why this works
Breaking things down into small, manageable tasks is generally a good idea for any project of any type, in almost any domain of life.
Gathering independent estimates from a panel of experts is also a very sound strategy. It has been generally found that the average of a number of estimates is often much more accurate than any individual estimator.
“Wisdom of the crowd” estimation is a similar concept, but we are using a smaller group of experts.
For a set of tasks that are independent, a Monte Carlo simulation is a well-established way of thinking about the ‘likely’ outcomes. Most retirement planning systems use Monte Carlo simulation to generate those plans. Many other systems use Monte Carlo as well.
This approach (IMO) ends up being the best of both worlds. If you have a group of developers, they will naturally estimate different tasks at different lengths of time. Some people are naturally conservative, some are optimistic. Some have better understanding of some tasks than others. Capturing the average of those estimates is a great way to get the likely time required for any given task.
Having said that, sometimes tasks take far longer (or far shorter) than estimated, because of unknown requirements or new approaches. The Monte Carlo simulation histogram helps identify the ‘shape’ of the project, and identify if those tasks that might have hidden complexity (or hidden simplicity) are making a major difference in the results. Humans have a hard time properly calculating the likelihood of rare events. Monte Carlo helps us avoid that.
Why ‘classic’ estimating sucks
In my experience, the ‘classic’ way to estimate software projects generally works like this:
Break the work down into fairly large tasks.
A single person (often an architect) makes fairly arbitrary single-number time estimates for those tasks.
A project manager adds up those estimates, adds various fudge factors, and comes up with a final estimate.
If the project manager doesn’t like the estimates, he or she will often push back on the architect to make the estimates smaller.
This estimate is presented to leadership as the number of hours.
In my experience, this ‘classic’ approach is frustrating for everyone involved:
For the architect, it requires making estimates for things that are not yet well-understood, and capturing that not-well-understood thing with a single number. If the project takes longer than expected, the development team will often be criticized for ‘missing’ the estimate, and resent the architect for underestimating the work.
For the project managers, with the padding and fudge factors to manage uncertainty, the end result is a no-win situation - if it takes less time than estimated, you’ll be accused of padding your numbers, and if it takes more time, you’re causing headaches for the organization, budget challenges, etc.
For the decision makers, the process is opaque, and the output timeframe is not really something in which they can have any confidence.
If the decision makers try to dig down into the numbers, the project manager will either push back (because they don’t want to argue about the amount of padding) or the decision maker will see the padding, often be skeptical, and argue about it.
Why this approach might be better
Among the many nice things of this Delphi-Monte Carlo hybrid method, you get a lot of transparency and reduced anxiety across the board:
The individuals doing the estimates are contributing to a dataset. They are not directly responsible for the final estimate, and if they are concerned about complexity of certain tasks, they can provide a high estimate, which is factored into the results.
The group estimate also provides some protection against “bullying”. A decision maker or project manager can argue with a single person about a high estimate. But arguing with an entire team of people is much more rare1.
The project manager can be fully transparent - every task can be shown to the decision makers, the process can be described and walked through, and the use of Delphi and Monte Carlo for generating estimates is well-established.
In addition, because the output is a confidence interval, it generally is not treated in the same way as a specific estimate. In the scenario “We have 80% confidence it will take less than 150 hours” and it takes 100, you’ve met the confidence criteria.
Note: In principle, 1 out of every 5 projects should take longer than your 80% confidence interval estimate. In practice, the project manager will probably put a lot of effort into making sure that the 80% estimate is rarely exceeded.
Because, as mentioned before, people have a hard time properly calculating rare events.
The decision maker has a lot more information. The task estimates are transparent. The confidence interval is basic math, not an arbitrary guess (even if somewhat educated).
It becomes easy to identify tasks that are outliers. This, in turn, provides the decision maker with the consideration of allocating early time and resources to rein-in those outliers (for example, by having the developers create prototypes or spikes of the risky tasks).
It gives the decision maker a lever to pull: “What about 70% confidence instead of 80%? What about 90% instead of 80%”. That ability to adjust the forecast is engaging and empowering. It also makes the process seem much less arbitrary than the ‘classic’ approach to estimation.
The one area where this can be abused is when the decision make says ‘what is the 50% confidence interval?’ and then demands that the team meet that (lower) estimate. Luckily, in my experience, most competent decision makers are not that cruel or arbitrary2.
Conclusions
I’ve been using this approach personally for a long time, and it’s served me well. Reading Kevin’s article inspired me to document it publicly for others to consider. If you have opinions/thoughts/suggestions/etc, please feel free to let me know: johnbr@paclabs.io
And if you happen to need any help with Policy-as-Code consulting/analysis/design/vendor recommendations/etc, hit me up!
Unless the decision maker or project manager is a raging narcissist who is certain that everyone else is an idiot
If you’re working for leadership that argues with entire groups over estimates and insists that teams meet estimates made with 50% confidence, you should probably find a new workplace